


Armağan Amcalar PRO
Armagan is the founder of Coyotiv GmbH, and is currently on a mission to bring a scalable and nimble engineering culture to startups and enterprises. Armagan is a public speaker, a mentor and a lecturer.
Diva Conference
July 26, 2025
Armağan Amcalar
CEO @ Coyotiv GmbH
CTO @ OpenServ, CTO @ Neol
dashersw
dashersw
dashersw
dashersw
dashersw
dashersw
|
Türkçe |
|
göz damlası |
|
saç fırçası |
|
diş macunu |
|
araba lastiği |
|
mutfak dolabı |
|
bahçe kapısı |
|
okul servisi |
|
bina girişi |
|
ev anahtarı |
|
el kitabı |
|
English |
|
eye drops |
|
hair brush |
|
toothpaste |
|
car tire |
|
kitchen cupboard |
|
garden gate |
|
school bus |
|
building entrance |
|
house key |
|
handbook |
dashersw
|
Turkish |
|
güneş krem-i |
|
el krem-i |
|
bebek bez-i |
|
çay kaşığ-ı |
|
çöp kutus-u |
|
kitap raf-ı |
|
güneş gözlüğ-ü |
|
yağmur-luk |
|
şemsiyelik |
|
şekersiz kahve |
|
yağlı boya |
|
balıkçı |
|
English |
|
sunscreen |
|
hand cream |
|
diaper |
|
teaspoon |
|
trash can / bin |
|
bookshelf |
|
sunglasses |
|
raincoat |
|
umbrella stand |
|
black coffee / coffee without sugar |
|
oil paint |
|
fisherman |
dashersw
dashersw
You are a product review analyzer for an e-commerce platform like Amazon. Your task is to analyze customer reviews and assign a sentiment label based on nuanced heuristics. Your goal is not only to detect surface-level positivity or negativity, but also to weigh intent, intensity, and relevance.
Follow these rules and decision-making heuristics carefully:
General Tone
If the reviewer explicitly uses words like “love,” “perfect,” “highly recommend”, assign Positive.
If the review uses phrases like “waste of money,” “terrible,” “never again”, assign Negative.
If the review is mixed (e.g. “great quality but too expensive”), proceed to Rule 2.
Aspect Balance
If both positive and negative aspects are mentioned, count the number of positive vs. negative statements.
If positives outnumber negatives by 2:1 or more, assign Positive.
If negatives dominate, assign Negative.
If roughly equal, assign Neutral.
dashersw
Expectation vs. Reality
If the reviewer says the product didn’t meet expectations (e.g., “I thought it would be bigger”), and expresses disappointment, reduce sentiment by one level (Positive → Neutral, Neutral → Negative).
If expectations were exceeded (e.g., “wasn’t expecting much, but it impressed me”), increase sentiment by one level.
Sarcasm Detection
If a sentence sounds positive but is followed by a contradiction or negative outcome (e.g., “Just great—it broke in two days”), treat it as Negative.
Use sarcasm cues like “yeah, right,” or overly formal praise for mundane items.
Star Rating Override
If a reviewer gives a high star rating but the text is clearly negative, label it as Inconsistent.
If the star rating matches the review text, you may use it to confirm your label.
dashersw
Review Usefulness
If the review is very short (e.g., “Good.” or “Don’t buy.”), and lacks context, assign Ambiguous.
If it includes usage experience, comparisons, or detailed pros and cons, treat it as Informative, and apply the above rules.
Keywords That Change Sentiment Context
Words like “cheap” can be either positive (“cheap and works well”) or negative (“feels cheap”). Check surrounding context before deciding.
“Fast” is positive for delivery, neutral for product speed, and negative if used in degradation (“stopped working fast”).
Review: [original review text here]
Sentiment: [Positive / Negative / Neutral / Ambiguous / Inconsistent]
Reasoning: [brief explanation of rule path followed]
You are expected to analyze like a human would, with judgment, pattern recognition, and contextual understanding.
dashersw
Attention is your friend
Attention is your enemy
Attention needs attention
dashersw
or too short?
or too ambiguous?
or too focused?
or misleading?
dashersw
dashersw
dashersw
dashersw
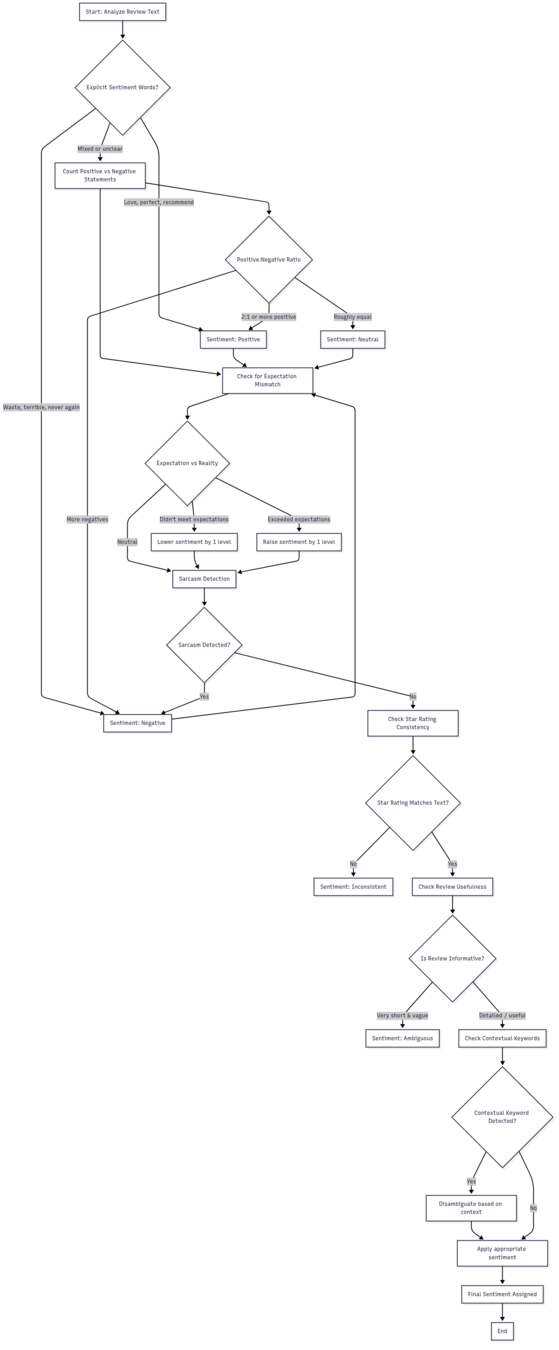
flowchart TD
A[Start: Analyze Review Text] --> B{Explicit Sentiment Words?}
B -->|Love, perfect, recommend| S1[Sentiment: Positive]
B -->|Waste, terrible, never again| S2[Sentiment: Negative]
B -->|Mixed or unclear| C[Count Positive vs Negative Statements]
C --> D{Positive:Negative Ratio}
D -->|2:1 or more positive| S1
D -->|More negatives| S2
D -->|Roughly equal| S3[Sentiment: Neutral]
C --> E[Check for Expectation Mismatch]
S1 --> E
S2 --> E
S3 --> E
E --> F{Expectation vs Reality}
F -->|Didn't meet expectations| L1[Lower sentiment by 1 level]
F -->|Exceeded expectations| L2[Raise sentiment by 1 level]
F -->|Neutral| G[Sarcasm Detection]
L1 --> G
L2 --> G
G --> H{Sarcasm Detected?}
H -->|Yes| S2
H -->|No| I[Check Star Rating Consistency]dashersw
I --> J{Star Rating Matches Text?}
J -->|No| S4[Sentiment: Inconsistent]
J -->|Yes| K[Check Review Usefulness]
K --> L{Is Review Informative?}
L -->|Very short & vague| S5[Sentiment: Ambiguous]
L -->|Detailed / useful| M[Check Contextual Keywords]
M --> N{Contextual Keyword Detected?}
N -->|Yes| O[Disambiguate based on context]
O --> P[Apply appropriate sentiment]
N -->|No| P
P --> Q[Final Sentiment Assigned]
S1:::positive
S2:::negative
S3:::neutral
S4:::inconsistent
S5:::ambiguous
Q --> End[End]dashersw
dashersw
dashersw
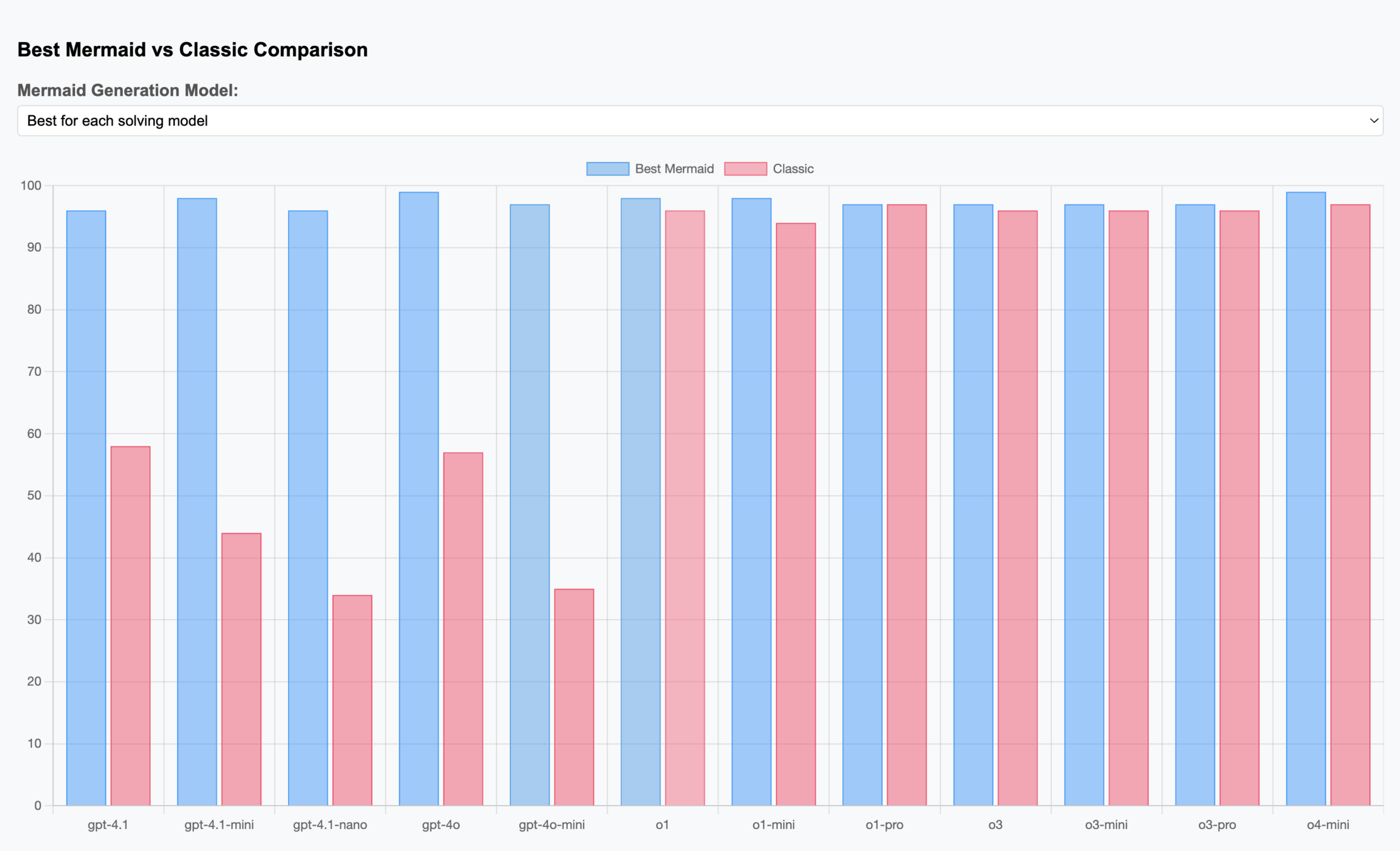
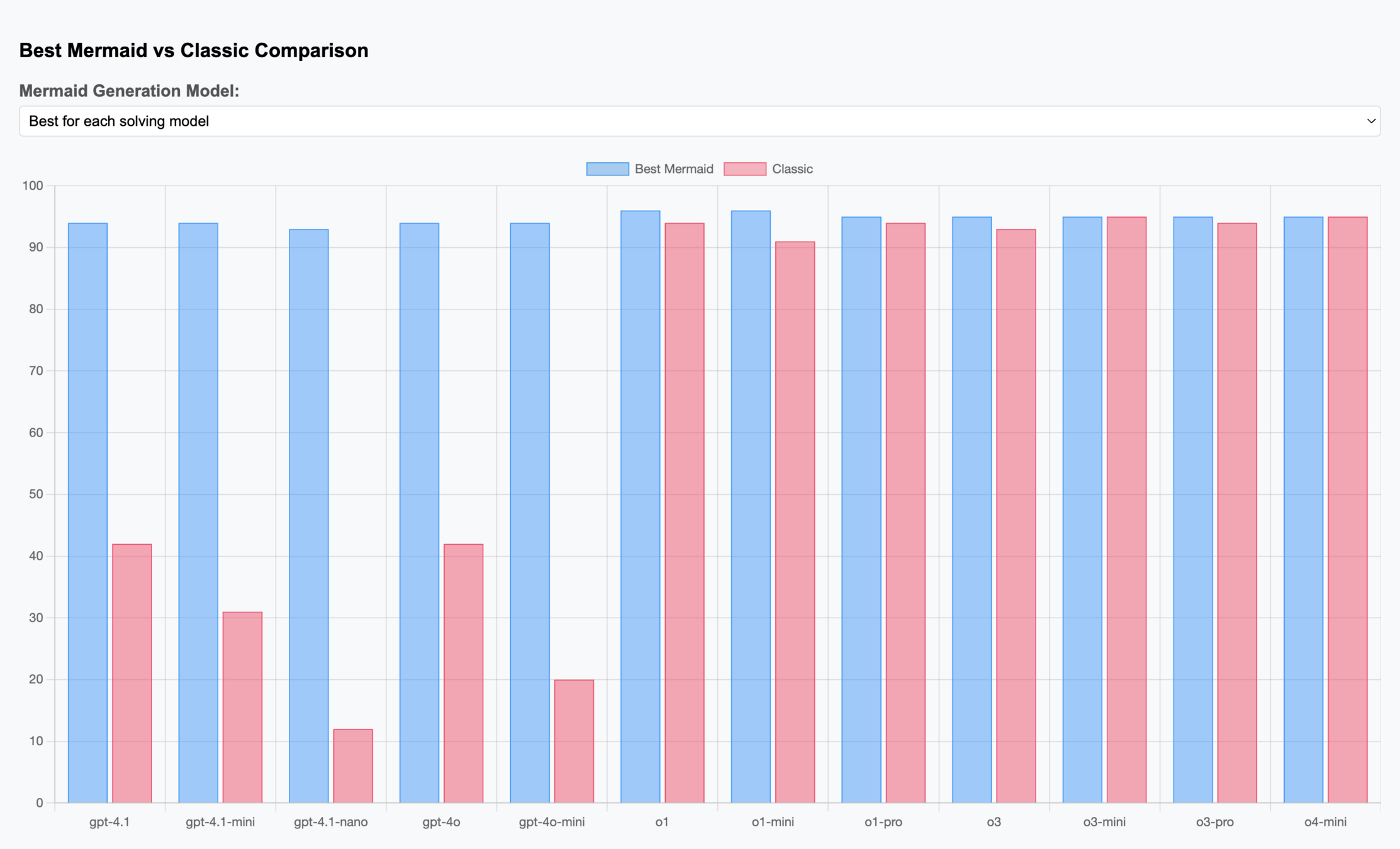
GSM-8K
dashersw
GSM-HARD
dashersw
dashersw
dashersw
dashersw
dashersw
Armağan Amcalar
dashersw
By Armağan Amcalar
Our journey towards Artificial General Intelligence continues, moving past the foundational questions of what constitutes an intelligent system to the critical challenge of how we build one. In this second installment, we venture Beyond Words to confront the core limitation of modern LLMs: their struggle to reliably execute complex logic when guided solely by the ambiguities of natural language. This keynote argues that the next significant leap in AI capability will not come from larger models, but from a more sophisticated architecture of communication. We will explore a powerful methodology for engineering trustworthy agents by moving from imprecise prompts to a formal Process-as-Code framework using flowchart syntax. By defining logic with the clarity of a blueprint, we can construct agents capable of predictable, multi-step reasoning and autonomous execution. Join us to explore this essential evolution in AI interaction and discover a practical architecture for building systems that can truly reason—a crucial step on the path to AGI.



